|
Audio tuned to how you hear |
|
|
 |
|
No two people hear sound the same way. Differences in hearing sensitivity, listening preferences, environments, and devices mean that a one-size-fits-all audio tuning often falls short. Sound Personalization adapts audio output to the individual listener, improving clarity, comfort, and overall listening experience across speech, music, and environmental sound. Powered by PersonaSound™, Alango’s Sound Personalization technology enables user-specific sound profiles that are applied in real time, directly on the device.
Sound Personalization is built around two complementary personalization methods. Both methods generate a user profile that feeds the same adaptive audio processing engine and may be used independently or together.
Best Sound Point – Preference-Based Personalization Best Sound Point (BSP) is an Alango personalization method. BSP is not a hearing test and does not attempt to measure hearing thresholds. Instead, BSP is a self-guided listening process in which users are presented with a rectangular grid where each square corresponds to a “profile” with its specific audio, voice or hearing enhancement parameters. Users listen to streamed, pre-recorded or live audio content and select the profile (squire on the grid) that sounds most natural, clear, and comfortable to them. 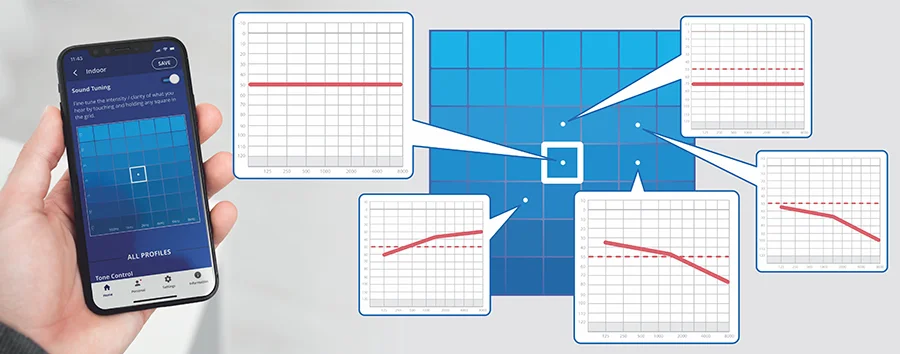 Key characteristics of BSP:
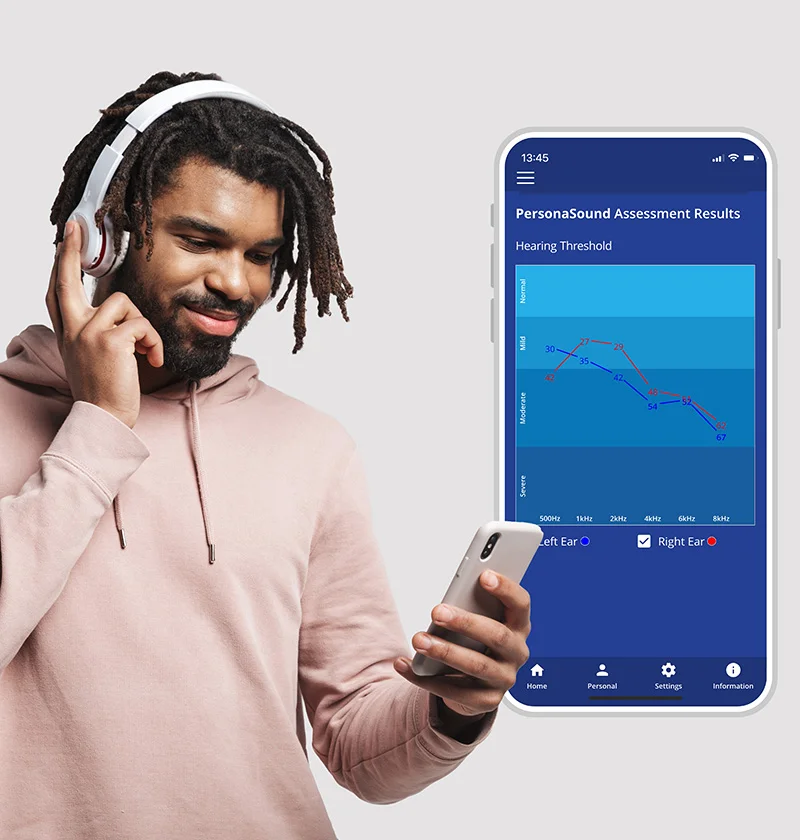
Audiogram-Based Personalization For scenarios where a more scientific or measurement-driven approach, Sound Personalization also supports audiogram-based personalization (threshold-based compensation). In this method, users listen to calibrated tones across multiple frequencies and adjust each tone until it is just audible thus identifying his or her hearing threshold at various frequencies. The resulting audiogram represents a frequency-specific hearing sensitivity profile. Audiogram-based personalization is particularly relevant when:
Audiogram-based personalization does not replace BSP. Users may further refine their listening experience using BSP on top of an audiogram profile, combining objective correction with subjective comfort.
Personalized Compensation (Not Simple EQ) Sound Personalization is not based on traditional equalization (EQ). A conventional EQ applies fixed gain adjustments by frequency, regardless of signal level. Human hearing, however, is level-dependent: quiet sounds often require more amplification, while louder sounds should be controlled to avoid discomfort. Alango applies personalization through Wide Dynamic Range Compression (WDRC), using frequency-dependent and level-dependent gain that dynamically adapts to both the incoming signal and the user’s personal profile. This approach enables:
Sound Personalization runs locally on the device, with no cloud dependency required. User profiles are stored and applied in real time by the device’s DSP, ensuring low latency and consistent performance even without network connectivity. The resulting profile is applied consistently across supported content types, including voice calls, media playback, and environmental audio.
Sound Personalization can be integrated into a wide range of consumer and automotive audio platforms, including earbuds, headphones, smart speakers, TVs, PCs, infotainment systems, and hearing-assist devices. PersonaSound™ is designed to scale across SoCs and DSP architectures, enabling OEMs to offer differentiated, personalized audio experiences without redesigning their entire audio stack. Alango offers Sound Personalization as part of multiple DSP packages: These modules run efficiently on major SoCs with minimal MIPS and memory required. |