Posted by Alexander Goldin

| Many of you probably remember “Open Sesame” – the first documented voice trigger in the story of "Ali Baba and the Forty Thieves" in "One Thousand and One Nights". In the story, Ali Baba overhears the 40 thieves saying "open sesame". His brother later confuses Sesame with the names of other grains becoming trapped in the magic cave. It took humans some time, but the intelligence of the magic cave is finally here. There is a growing number of consumer products that are activated by a word or phrase. Some of these products work really well competing or even outperforming the magic cave “Open Sesame” voice trigger in quiet conditions. However, today it is not enough. Market demands that voice trigger and the following automatic speech recognition work reliably in noisy conditions and from large distances. Such performance cannot be achieved by a single, consumer grade microphone due to its, relatively, high self-noise (low signal-to-noise ratio) as well as omnidirectional sound pick-up (polar) pattern. Healthy human ear is much less noisy and humans have two ears enabling us to separate sounds coming from different directions. Try to record and listen a distant sound using a microphone built into your laptop or mobile phone. You will notice a very big difference compared to what you heard by your ears while recording. We need to improve the microphone sound quality significantly to be able to compete with ourselves in voice recognition. The natural solution is to try to utilize more microphones separated in space (microphone arrays). Since, potentially, we are not limited in the number of microphones, we can hope to beat the voice trigger recognition performance of the human ear (and brain) sooner or later. There were multiple attempts to use microphone arrays to improve the quality of speech recognition by computer, some of them with a good success. Today, Amazon Echo is probably the best and most widely known example. Echo utilizes 7 microphones located at the top with 6 microphones placed in a circle and one in the center. Amazon Echo is activate by the keyword “Alexa”. Echo’s voice trigger is extremely robust to ambient noises demonstrating reliable voice detector recognition as well as its direction finding. It will not be exaggeration to say that Amazon Echo today sets the gold standard to the whole consumer electronics industry, the standard that is not easy to beat, but not at all impossible. We will soon publish our tests results that we have received with the same microphone array configuration as Amazon Echo does (6+1 microphones). However, in this post I would like to share with you results of voice trigger recognition enhancement for another application – smartphones. Smartphone has long time ago evolved into something that is more “smart” than “phones”. For many people, it is an opening to the world, the entrance to the magic cave of communication, information and entertainment. It is only natural if this entrance will be operated by user’s voice, the voice trigger. Like the magic cave, it needs to be always on, always listening. Moreover, it must be reliable and noise robust. Eventually, it can even outperform the magic cave algorithm by recognizing its master’s voice rejecting the access of unwanted “guests”. To make the magic a usable reality, the audio signal recorded by the smartphone and passed to the voice trigger recognizer must be strong, clean and free of ambient noises and reverberation. To achieve it for various use cases, we need more than one microphone, an Algorithm and a Digital Signal Processing means (DSP) where the Algorithm will crunch numbers transforming several original, noisy microphone signals into a clean, enhanced one. There are various technical difficulties associated with this idea such as an increased power consumption due to extra microphones and associated digital signal processing. We will not discuss most of them in this post. Instead, we will now focus on a realistic placement of multiple microphones in a smartphone and benefits in sensitivity and reliability of voice trigger recognition associated with using multiple microphones. Of course, the Algorithm is the most important enabling factor and we must say a few words about it as well. We, in Alango Technologies, have been developing multi-microphone far-voice pick up technologies for a number of years. In 2013 at Consumer Electronics Show in Las-Vegas, we demonstrated an 8-microphone array mounted on the top of a television allowing the user to talk from 5 meters in a soft voice. Our idea was to enable high quality audio for then emerging free video call services such as Skype. While performing very well technically, it generated a little commercial interest. Televisions were too cost sensitive to incorporate more than two microphones and users were ready to live with a mediocre voice quality for low price. Introduction of Amazon Echo and its success heavily relying on speech recognition has changed the situation completely. We started receiving requests for voice enhancement technologies allowing various stationary and mobile devices to compete with Amazon Echo in quality with the same or smaller number of microphones. We decided to utilize our prior experience and reuse our far-field speech algorithms designed for voice communication for automatic speech recognition enhancement. This post is about what we (in Alango) can do with it to help your phone to pick your voice from a large distance in a noisy environment. As some of you know, most modern smartphones already use two microphones. The second microphone is, generally, located at the top of the devices and it is mainly used to reduce ambient noises when the user holds the device in his or her hand. Different algorithms do it with different success (see a comparison of different phones here www.alango.com/acoustic-lab-phones-results.php ). Our task here is different. The device is lying on table, probably in a power saving mode, with the user located 1-4 meters from it. The device is just listening for the key phrase (voice trigger). When it recognizes it, it wakes up and starts the dialog. In our test setup, we used a phone dummy mockup with four microphones in realistic locations. Two microphones were located at the bottom and two at the top.  From the acoustic performance perspective, we would like to place additional two microphones at the sides, but this is, probably, not a realistic option from mechanical point of view. With our mockup, we were able to simulate performance of Alango voice enhancement combined with Sensory Inc. Truly Hands-free voice trigger technologies for different smartphones with 2, 3 and 4 microphones respectively. We have made about 500 recordings with different voices at different distances and directions and in different noise conditions. Here is an exempt from full results showing the dependence of the percentage of recognized utterances of the voice trigger (“hit rate”) depending on the distance with some diffused noise coming from side. In all test the noise level was about 75dB SPL at the phone location on the table in the center of our meeting room. We used different voice levels measured at 3 centimeters distance from the mouth simulator (Mouth Reference Point) as follows (in dB SPL):
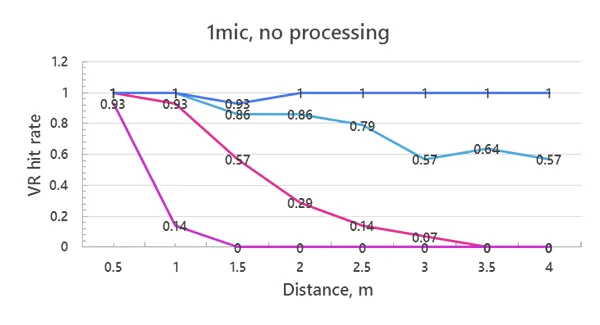
Here are the results without any signal enhancement (one microphone):
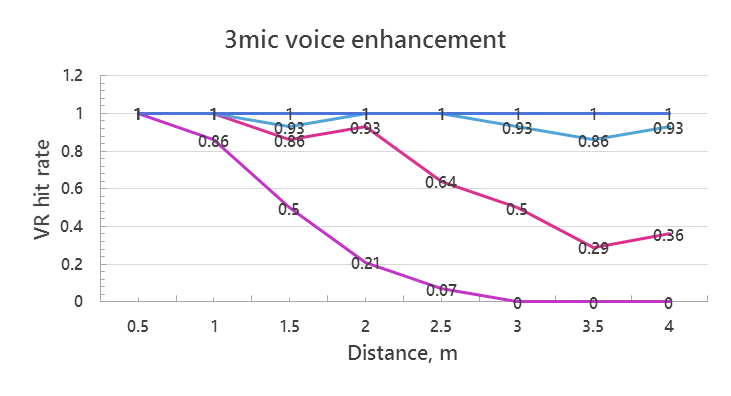
And here is what we can do utilizing acoustic beamforming and voice enhancement algorithms using 3 microphones:
The voice trigger recognition improvement is very significant, especially at low SNR. Considering that, most smartphones use two microphones and some already incorporate three in the same configuration, it is also a “software only” technology improvement. The full results together with the description of test conditions and audio examples before and after signal enhancement can be found in this Power Point Show: Far-Field Smartphone Voice Recognition Enhancement (PPSM version) Its compact PDF version (without audio examples) can be downloaded from here: Far-Field Smartphone Voice Recognition Enhancement (PDF version) I hope you have found the above information interesting. I am looking forward receiving your comments, ideas and suggestions. |